Foundations of LLMs
1. The Transformer Architecture
Before You Read
- Explain why attention replaced recurrence for large-scale language modeling.
- Distinguish encoder, decoder, and decoder-only Transformer use cases.
- Trace how token embeddings, positional information, attention, and feed-forward layers cooperate.
Working Model
A Transformer is a stack of context mixers. Each layer lets every token look across the sequence, collect useful evidence, and rewrite its representation with richer context. The model is not storing sentences as text; it is continuously transforming vectors so the next-token distribution becomes easier to predict.
At the heart of modern AI lies the Transformer. Introduced in the seminal 2017 paper "Attention Is All You Need" by Vaswani et al., this architecture revolutionized natural language processing and paved the way for modern Large Language Models (LLMs).
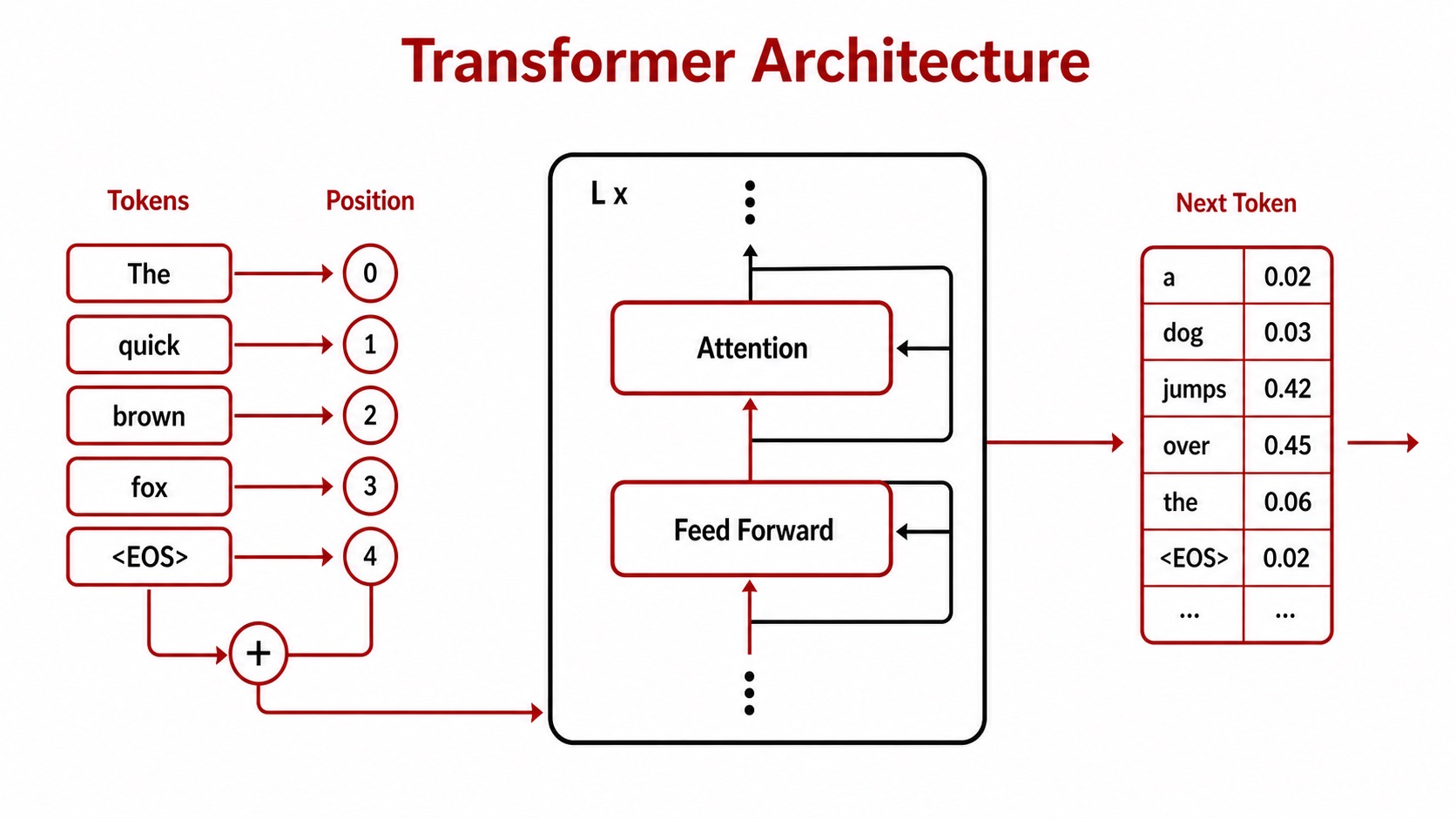
Before Transformers, models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) processed text sequentially. This meant they read a sentence word-by-word. This sequential nature had two major flaws:
- Slow Training: You couldn't process the 10th word until you processed the 9th.
- Forgetting Context: By the time the model reached the end of a long paragraph, it often "forgot" what the beginning was about.
Key Innovations of the Transformer
-
Parallelization: Transformers process all words in a sequence simultaneously. This drastically reduces training time and allows for massive scaling across thousands of GPUs.
-
Self-Attention: This mechanism allows the model to weigh the importance of different words in a sentence relative to each other, regardless of their position.
-
Positional Encoding: Since the model processes all words at once, it inherently loses the order of words. Positional encodings are mathematical vectors added to the input embeddings to give the model a sense of sequence and order.
The Encoder-Decoder Structure
Originally, the Transformer was designed for translation and had two parts:
- Encoder: Reads the input text (e.g., English) and creates a dense mathematical representation of its meaning.
- Decoder: Takes that representation and generates the output text (e.g., French) step-by-step.
The Rise of Decoder-Only Models
Modern LLMs like GPT (Generative Pre-trained Transformer) are typically Decoder-only models. They are trained on a deceptively simple objective: predict the next word.
By playing this "guess the next word" game across trillions of words from the internet, the model is forced to learn grammar, facts, reasoning, logic, and even coding. It builds an internal world model just to become accurate at predicting what word comes next.