Embeddings & Vector Spaces
1. What are Embeddings?
Before You Read
- Explain embeddings as dense vectors that preserve useful semantic relationships.
- Describe how queries and documents become comparable in the same vector space.
- Recognize the difference between semantic closeness and factual correctness.
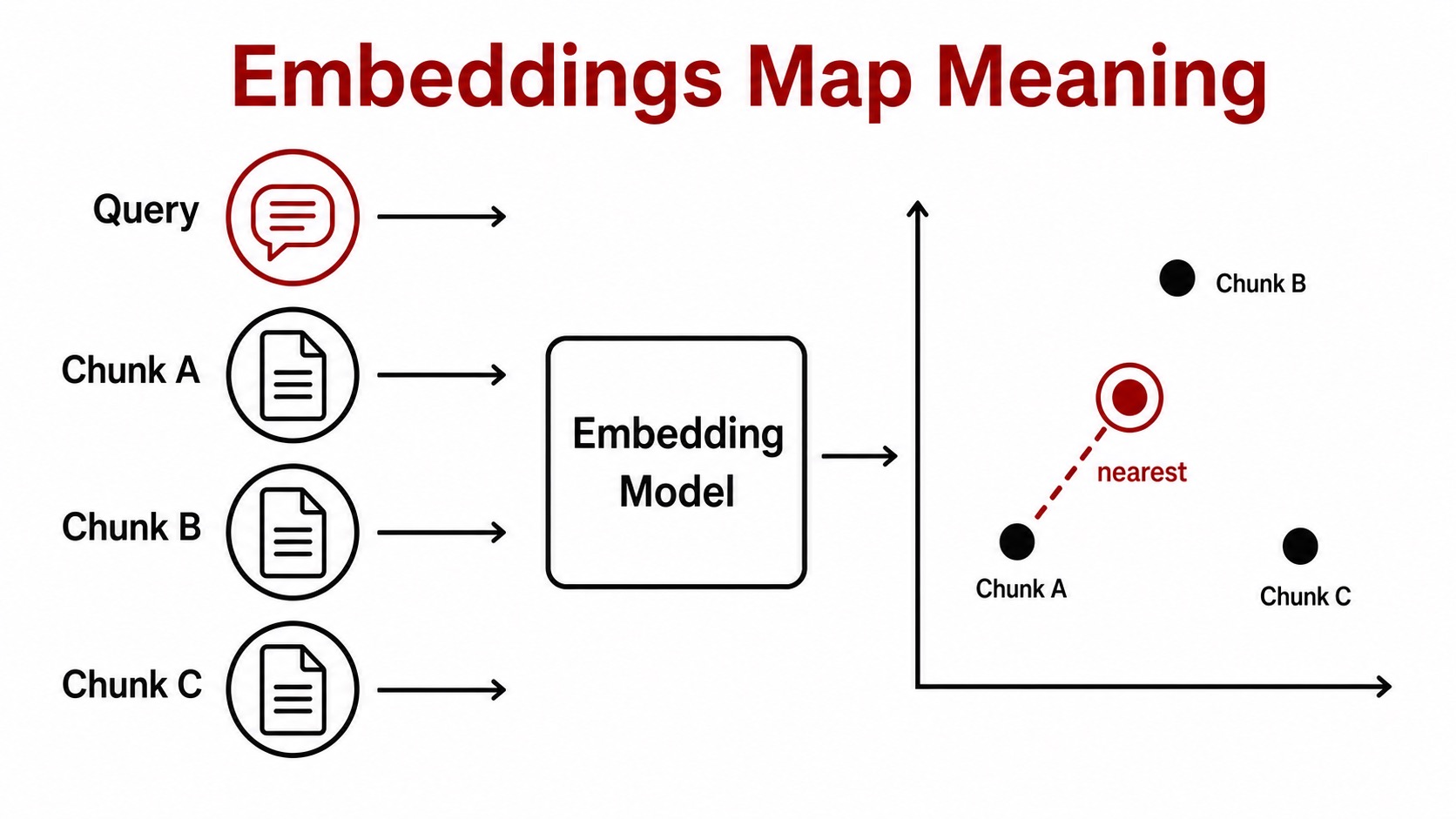
Working Model
An embedding model compresses text into coordinates. Nearby points usually express related meaning, so retrieval becomes a nearest-neighbor search. The vector is useful for finding candidates, not for proving that a candidate answers the question.
To a computer, text is just a sequence of meaningless characters. To perform semantic search or Retrieval-Augmented Generation (RAG), we need a way to represent the meaning of text mathematically. This is where Embeddings come in.
An embedding is a dense vector (a list of numbers) that represents the semantic meaning of a piece of text in a high-dimensional space.
From One-Hot Encoding to Dense Vectors
Historically, NLP used techniques like One-Hot Encoding or Bag-of-Words. If your vocabulary had 10,000 words, the word "apple" might be represented as a vector of 10,000 numbers, where all are 0 except for a single 1 at the index for "apple".
- The Problem: These vectors are incredibly sparse (mostly zeros) and capture absolutely zero meaning. The mathematical distance between "apple" and "orange" is exactly the same as the distance between "apple" and "car".
In 2013, Google researchers introduced Word2Vec, which popularized dense embeddings. Instead of 10,000 dimensions, words were mapped to dense vectors of, say, 300 dimensions, where every number is a non-zero float.
The Magic of Semantic Space
In this high-dimensional space, words with similar meanings are physically closer together. The model learns these relationships by reading massive amounts of text and observing which words appear in similar contexts (the Distributional Hypothesis).
The most famous demonstration of this is vector arithmetic:
Vector("King") - Vector("Man") + Vector("Woman") ≈ Vector("Queen")
Modern Transformer Embeddings
While Word2Vec embedded individual words, modern LLMs embed entire sentences, paragraphs, or even documents. When you pass a sentence into an embedding model (like OpenAI's text-embedding-3-small), the Transformer processes the text using self-attention and outputs a single vector (e.g., 1,536 dimensions) that encapsulates the meaning of the entire sequence.
Example: Generating an Embedding with OpenAI (Python)
from openai import OpenAI client = OpenAI() response = client.embeddings.create( input="The bank of the river was muddy.", model="text-embedding-3-small" ) print(response.data[0].embedding) # Output: [-0.023, 0.014, -0.005, 0.081, ...] (1536 dimensions)